Pretrained transformers adapt to new sequence tasks by zero-shot prompting, yet relational domains have lacked architectures that transfer across datasets and tasks. The Relational Transformer (RT) is a schema-agnostic architecture pretrained on diverse relational databases and applied directly to unseen datasets and tasks, with no task- or dataset-specific fine-tuning and no retrieval of in-context examples.
The challenge of relational data
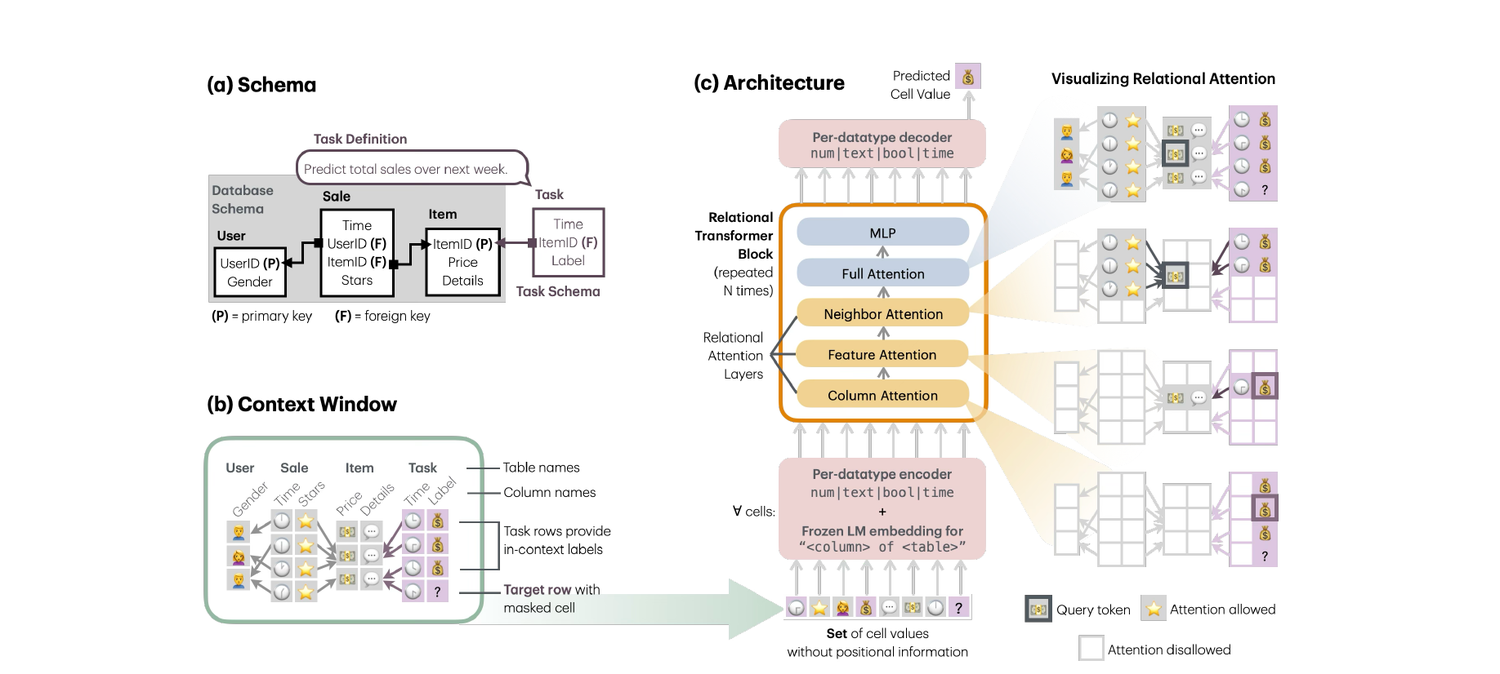
A relational database is not a single table. It is a collection of tables linked through inter-table relationships. Each table is a set of rows, and every row is a set of cells, one per column. Feature columns hold numeric, text, and datetime values, while ID columns uniquely identify rows and connect them across tables. Every table has a primary key, and some tables carry foreign keys that reference primary keys elsewhere. This induces a graph, with foreign-key-to-primary-key links denoted F→P and the reverse incoming links P→F. Many databases are also temporal, so predicting an event at time t must use only information available before t, otherwise it risks temporal leakage. Because schemas vary so widely, a transferable model must be schema-agnostic and encode multi-table structure directly.
Predictive tasks as masked token prediction
RT casts prediction as masked token prediction over cells. A broad class of problems fits this frame. Autocomplete tasks mask a value in an existing feature column, for example a user's missing age. Forecasting tasks predict something that has not yet happened, for example whether a user will churn in the next 30 days. Forecasting targets do not exist in the original database, so RT introduces a dedicated task table that stores the labels, foreign keys to the relevant entities, and a timestamp for the prediction horizon. Only one task table is active at a time, its rows act as seed rows for context, and the model treats it as an ordinary table. This is what lets a single pretrained model serve arbitrary downstream tasks zero-shot, with past task rows providing in-context labels rather than retrieved few-shot examples.
Architecture
RT serializes a database into cell tokens that carry their relational context, attends across that structure with a purpose-built mechanism, and is trained by masked prediction. It comprises four components.
Task table prompting
The prediction task is specified as a table appended to the database, so a new task corresponds to new input rather than a new model head. This augments the database with task-specific context and enables zero-shot prediction across diverse schemas.
Cell-level tokenization with metadata
Each database cell becomes an individual token, annotated with its table and column identity. Operating at the cell level lets one model read schemas it has never encountered and explicitly model dependencies across rows, columns, and tables.
Relational Attention
A novel attention mechanism with specialized masks over columns, rows, and primary-foreign key links, encoding the database graph directly into the transformer rather than flattening it away.
Masked-token pretraining
Pretrained on RelBench databases by predicting masked cells, RT learns transferable relational structure that generalizes to new databases and tasks in a single forward pass.
Cell tokenization
A cell is represented by the triple (v, c, t), its value, column name, and table name. The value is encoded by datatype, then combined with a frozen language-model embedding of the schema phrase “<column name> of <table name>”, for example “price of product” or “age of user”.
| Datatype | Value encoding |
|---|---|
| numeric / boolean | Normalized per column, r = (v − μc) / σc |
| datetime | Converted to seconds, normalized globally, r = (v − μT) / σT |
| text | Embedded with a frozen text encoder, r = Etext(v) |
The token embedding is x = Wd r + W Eschema(c, t), where
Wd is datatype-specific and W is shared. For a masked cell,
the value term Wd r is replaced by a learned mask vector. RT uses
no positional encodings, because relational structure is captured directly by
its attention layers.
Context construction
Given a seed row, RT builds a context window of n cells (1024 in the released configuration) by expanding across primary-foreign key links with a bounded-width breadth-first search. All parent rows (F→P) are always included, child rows (P→F) are subsampled under a width bound w, and rows with timestamps later than the seed row are excluded to prevent temporal leakage. Once a row is selected, all of its non-missing feature cells are added to the context.
Relational Attention
The core of RT is a Relational Attention mechanism whose fundamental unit is the cell token. It
uses standard scaled dot-product attention augmented with a binary mask M that
controls which tokens may attend to which.
Attention(Q, K, V ; M) = Softmax( (Q K⊤ ⊙ M) / √dK ) V
For the cell at token i, let Col(i) be its column, Row(i) its row, and OutLinks(i) the rows pointed to by the foreign keys of Row(i). Four specialized masks define four attention types.
- Column attention. Attend only to cells in the same column,
M[q,k] = 1 if Col(k) = Col(q). Models the distribution of values within a column. - Feature attention. Attend to cells in the same row and in parent rows reached by foreign keys,
M[q,k] = 1 if Row(k) = Row(q) or Row(k) ∈ OutLinks(q). Equivalent to row-wise attention after joining a table with its parents, mixing the features of an entity. - Neighbor attention. Attend to child rows that reference the query,
M[q,k] = 1 if Row(q) ∈ OutLinks(k). Aggregates signals from incoming links, analogous to message passing in a graph neural network. - Full attention. A standard bidirectional layer,
M[q,k] = 1, restoring the expressive power of a Transformer.
Together these layers give the model an explicit encoding of database structure. They are implemented as sparse masks and compiled to efficient FlashAttention-based kernels via FlexAttention. The widget below reproduces the four masks exactly.
Output decoding and training objective
The transformer output for each token is processed by per-datatype cell decoders, one per datatype, and the decoder used for the final prediction follows the datatype of the masked cell. Boolean cells correspond to binary classification and numeric cells to regression.
The overall loss is the mean over all masked cells in a batch. Crucially, the same objective is used for both pretraining and fine-tuning, ensuring consistency between the two and contributing to RT's sample efficiency.
Experimental setup
All experiments use RelBench, which provides seven relational databases from diverse domains (rel-amazon, rel-hm, rel-stack, rel-avito, rel-event, rel-trial, rel-f1), each with forecasting tasks that are either binary classification or regression. To demonstrate transfer to a fully unseen dataset and task, RT is pretrained leave-one-database-out, separately for each target dataset on all tasks from the other datasets. The architecture is a 12-layer transformer with hidden dimension 256 and 8 attention heads, gated MLPs with SiLU activation, and frozen MiniLMv2 text embeddings, about 22M trainable parameters. Pretraining runs for 50k steps at a context length of 1024 cells; one pretraining run takes roughly two hours on eight A100 GPUs. Baselines span schema-agnostic methods (Griffin, and Gemma3 LLMs prompted with a serialized database subgraph), schema-specific methods (RDL-GNN, RelGNN, RelGT, RelLLM), and a non-neural EntityMean baseline that predicts the mean of an entity's past labels.
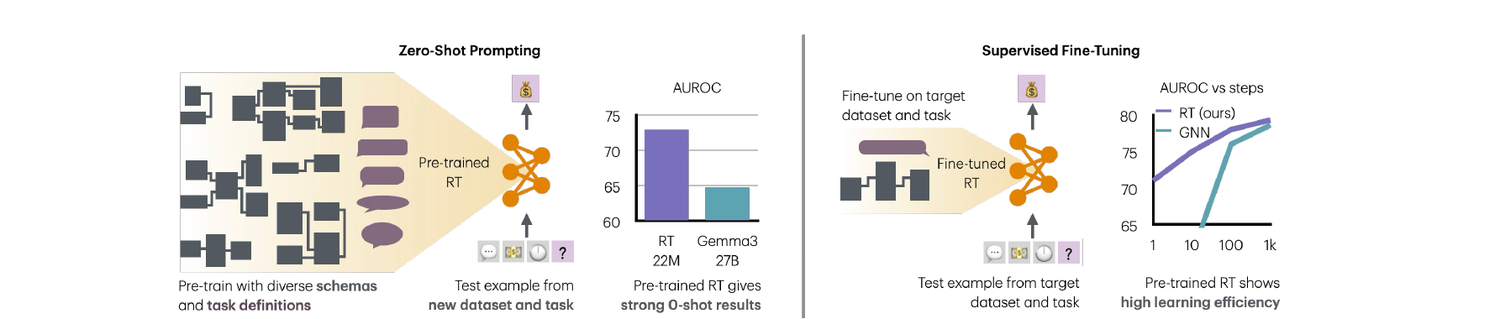
Zero-shot results
With the target dataset and task unseen during pretraining, RT averages 90.3% of fully-supervised AUROC, rising to 93.1% after brief continued pretraining on the target database, versus 83.7% for Gemma3-27B given an equivalent context as text. On classification, RT attains the best average AUROC and is the only method to consistently beat the EntityMean baseline. On regression, where the LLM baselines fail to produce meaningful predictions, RT is the only model to consistently achieve positive R².
Full per-task numbers for every RelBench task are reported in the paper and tracked on the RelBench leaderboard.
Supervised fine-tuning
Fine-tuned from its pretrained checkpoint, RT reaches state of the art with high sample efficiency. It attains the best mean over all baselines on both classification (77.2% AUROC) and regression (33.2% R²), and the pretrained initialization reaches the second-best baseline's performance with 10 to 100 times fewer training steps. Pretrained RT maintains its advantage throughout fine-tuning and is only matched late on classification tasks by training-from-scratch baselines.
- Classification AUROC. RT (pretrained) 77.2, the best result, ahead of RelGNN and RelLLM at 77.1 and RDL-GNN at 75.4.
- Regression R². RT (pretrained) 33.2, well ahead of Griffin at 19.5 and RDL-GNN at 14.3.
What drives zero-shot transfer
Ablations isolate why RT transfers. In order of importance, the drivers are the target entity's own past labels (self labels), column attention, feature attention, schema semantics, and finally other entities' labels.
The relational attention layers matter most on regression. Removing column attention drops the zero-shot R² from 22.8 to 11.9, the single largest effect, confirming that modeling the distribution of each column is central to transfer.
| Attention layer removed | none | column | feature | neighbor | full |
|---|---|---|---|---|---|
| zero-shot R² (%) | 22.8 | 11.9 | 18.8 | 22.0 | 23.7 |
Relational-attention-layer ablation, mean zero-shot R² over 8 regression tasks (Table 4). Column attention is the most important layer for transfer.
Summary. Relational structure, encoded directly into attention and learned by masked prediction, is sufficient to transfer across databases. It is a key ingredient for a foundation model over tables, and scaling the data behind it is the focus of PluRel.
Key takeaways
- A schema-agnostic, cell-level foundation model. Cell tokenization plus task-table prompting let one pretrained model serve unseen databases and tasks zero-shot.
- Relational structure belongs in the attention. Column, feature, and neighbor masks encode the database graph directly, and column attention is the single most important layer for transfer.
- Self labels and schema semantics carry the zero-shot signal. A target entity's own past labels dominate transfer, supported by column and feature attention and by the meaning of table and column names.
The paper also notes current limitations and directions for future work, including support for link-prediction tasks, richer use of key semantics, and foreign-key disambiguation.
Cite
title = {{Relational Transformer:} Toward Zero-Shot Foundation Models for Relational Data},
author = {Rishabh Ranjan and Valter Hudovernik and Mark Znidar and Charilaos Kanatsoulis and Roshan Upendra and Mahmoud Mohammadi and Joe Meyer and Tom Palczewski and Carlos Guestrin and Jure Leskovec},
booktitle = {The Fourteenth International Conference on Learning Representations},
year = {2026}
}