
Abstract
Relational Foundation Models (RFMs) facilitate data-driven decision-making by learning from complex multi-table databases. However, the diverse relational databases needed to train such models are rarely public due to privacy constraints.
We introduce PluRel, a framework to synthesize multi-table relational databases through three stages: modeling schemas with directed graphs, inter-table connectivity with bipartite graphs, and feature distributions via conditional causal mechanisms.
We demonstrate that RFM pretraining loss exhibits power-law scaling with synthetic database quantities and tokens. We show that synthetic database scaling improves generalization to real databases and provides strong foundation models for continued pretraining on real data, positioning synthetic data scaling as a promising approach for advancing relational foundation models.
Method
PluRel generates synthetic relational databases through three sequential stages, modeling databases at the schema level (table structure), the connectivity level (row-level relationships), and the feature level (cell values).
- Stage 1 · Schema: DAGs define table structure and relationships.
- Stage 2 · Connectivity: HSBMs populate foreign-key links.
- Stage 3 · Features: SCMs generate cell values with temporal patterns.
1Schema generation via directed graphs
Database schemas are represented as directed acyclic graphs (DAGs), where nodes correspond to tables and edges represent inter-table relationships. A topological ordering of the DAG determines the table generation sequence: initial tables are synthesized independently, while subsequent tables are generated conditionally on their parent tables. Tables are categorized as entity tables (out-degree ≥ 1) or activity tables (remaining nodes). The number of rows, feature columns, and graph topology are all configurable.
2Foreign-key generation via bipartite graphs
Row-level connectivity between table pairs is populated through primary–foreign key relationships. Each table contains feature columns, a primary key column indexing rows, and optional foreign key columns referencing parent table rows. A Hierarchical Stochastic Block Model (HSBM) controls row-level information locality, allowing rows to depend on many parent rows or a small subset, enabling flexible dependency modeling.
3Feature generation via structural causal models
Each table is associated with its own SCM defined by a causal graph encoding dependencies between variables. Feature columns correspond to a subset of SCM nodes, supporting numeric, categorical, and boolean types. Tables with foreign keys condition on feature nodes from parent table SCMs.
Temporal correlations are modeled through exogenous inputs combining trend (power-law), cycle (sinusoidal), and fluctuation (random noise) components. Node mechanisms use a projection–reconstruction design: predecessor values and parent table features project into a shared latent space via MLPs, aggregate with exogenous inputs, then reconstruct to the target data type.
Usage
Install the library from PyPI:
pip install plurelSynthesizing a complete relational database requires only a seed and a configuration object. The resulting dataset is fully compatible with RelBench:
from plurel import SyntheticDataset, Config
# create relbench compatible dataset
dataset = SyntheticDataset(seed=0, config=Config())
# create database which can be cached via relbench APIs
db = dataset.make_db()
Every aspect of generation is controlled by the Config object: table layouts, the
number of tables, row and column counts, and SCM parameters. For example, to bound the table
count or generate from an existing SQL schema:
from plurel import Config, DatabaseParams, Choices
config = Config(
database_params=DatabaseParams(
num_tables_choices=Choices(kind="range", value=[5, 10])
),
schema_file="path/to/schema.sql", # optional: generate from SQL schema
cache_dir="~/.cache/plurel", # optional: cache generated databases
)For large-scale generation, databases can be synthesized in parallel:
pixi run python scripts/synthetic_gen.py \
--seed_offset 0 \
--num_dbs 1000 \
--num_proc 16 \
--preprocessKey results
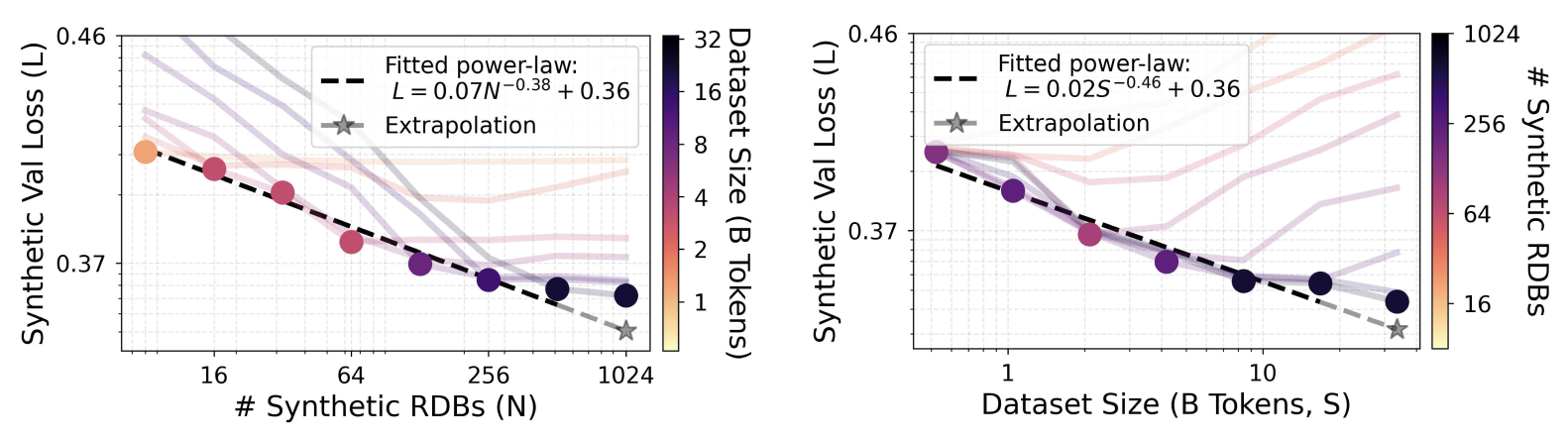
Scaling laws for data diversity and size
We investigate scaling along two axes: the number of synthetic relational databases N (diversity) and the number of pretraining tokens S (size). We find that the validation loss exhibits power-law scaling along both dimensions:
L(N) = AN · N−αN + CN L(S) = AS · S−αS + CS
We conduct a comprehensive grid of experiments across (N, S) ∈ {8, 16, 32, 64, 128, 256, 512, 1024} × {0.5B, 1B, 2B, 4B, 8B, 16B, 32B} tokens. Both N and S must be scaled simultaneously to optimize loss; scaling one dimension alone produces non-monotonic U-shaped curves indicating underfitting or overfitting.
RFM pretraining loss follows power-law scaling with both data diversity (N) and size (S), mirroring scaling laws observed in LLMs. Both dimensions must be scaled jointly for optimal performance.
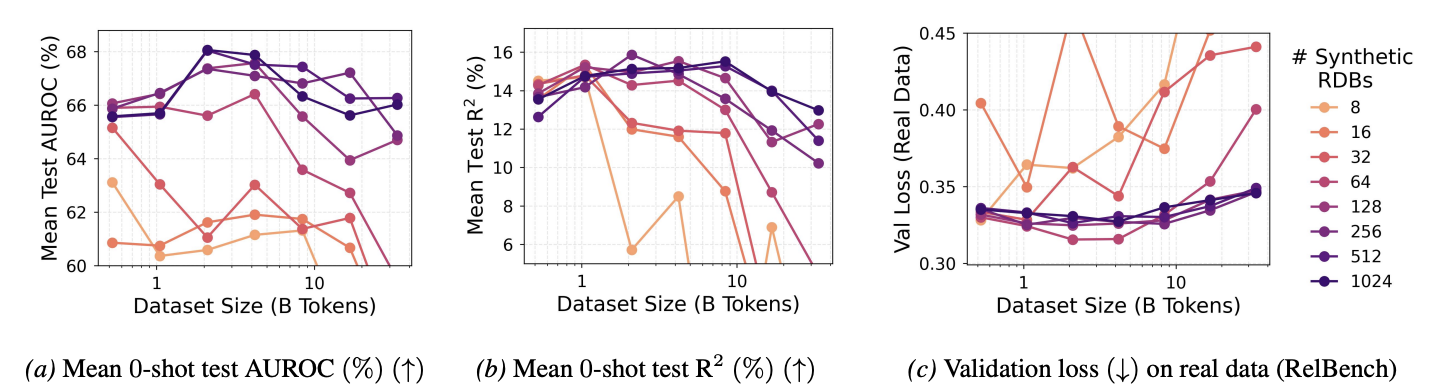
Generalization to real datasets
We evaluate whether synthetic pretraining benefits transfer to real-world relational databases from RelBench. We compute the masked token prediction loss on the validation splits of all 18 RelBench tasks using the same synthetic scaling configurations.
Low-diversity settings (8–32 synthetic databases) exhibit poor scaling on RelBench, where larger datasets tend to be suboptimal as loss curves show an upward trend. This undesirable behavior is mitigated as the number of databases increases, with benefits from scaling dataset size becoming evident at higher database counts. Models show consistent zero-shot transfer capability despite the distribution mismatch between synthetic and real data.
Scaling synthetic data diversity is critical for generalization. With sufficient database diversity, synthetic pretraining enables zero-shot transfer to real-world RelBench tasks.
Continued pretraining on real datasets
Synthetic pretraining creates effective base models for downstream tasks when combined with continued pretraining on real data. Using a leave-one-database-out protocol across six RelBench datasets, we show that synthetic + real pretraining consistently outperforms real-data-only pretraining:
Synthetic data alone is insufficient for robust zero-shot transfer, highlighting that continued pretraining on real data is critical for distribution alignment. The combination of synthetic and real pretraining yields particularly pronounced benefits for behavior-driven and continuous-valued prediction tasks.
Full per-task numbers for every RelBench task are reported in the paper and tracked on the RelBench leaderboard.
Synthetic + real pretraining outperforms real-only pretraining, with +1.2% mean AUROC and +3.0% mean R² gains. Synthetic pretraining provides a strong initialization for continued learning on real data.
Cite
title = {{PluRel:} Synthetic Data unlocks Scaling Laws for Relational Foundation Models},
author = {Kothapalli, Vignesh and Ranjan, Rishabh and Hudovernik, Valter and Dwivedi, Vijay Prakash and Hoffart, Johannes and Guestrin, Carlos and Leskovec, Jure},
journal = {arXiv preprint arXiv:2602.04029},
year = {2026}
}